On OpenAI o1

Andrew Bolster
Senior R&D Manager at Black Duck Software, driving data to make AI work
 Is LLM Smarter than a 12 year old?
Is LLM Smarter than a 12 year old?
Had a few people ask about the o1 models; at work we’ve requested preview access from Microsoft to get them added to our internal LLM Gateway, so we’ll just wait and see, but there’s been some interesting discourse on it so far.
My 2c is that this is OpenAI trying to take the chain-of-thought (aka ‘talking to yourself’) in house rather than people doing the intermediate steps themselves. (That means, instead of just running the token prediction, it’s a repeated conversation with itself, with OpenAI providing the ‘inner monologe’ and just magically popping out the answer). This is fine in principal, and is how we do multi-shot RAG among other things, but the two(three) critical parts of this for me are
a) They charge you for the tokens you don’t control (inner monologue)
b) They actively hide how this inner monologue is constructed, updated, and maintained, and threaten your account if you poke around.
[c) just so happens that Open AI is doing a funding round. Go figure]
All in all, I’ll stick to 3.5/4o and wrangle constructive context data to inform LLM usecases, in workflows that we know better than Sam et al. and make context-specific data/LLM agents that collaborate to be useful, rather than a one size fits all magical black box that you don’t own. But its fun to watch.
Highlights of the discourse I’ve come across:
-
UCAL Math Prof Terence Tao (Fields Medalist, no biggy) ran it through it’s paces and was less than impressed at its ‘reasoning’ https://mathstodon.xyz/@tao/113132502735585408
-
Simon Willison (PSF) is intrigued, and it can work out more than GPT 4o in ‘joke’ contexts, or things that need to be ‘unpacked’, but is gonna stick to 4o for now. https://simonwillison.net/2024/Sep/12/openai-o1/
-
Wharton’s Ethan Mollick has a pretty in depth review of getting o1 to do a crossword puzzle, and his observation at the end is ‘this is great but how do we keep a human in the loop for how much of this inner monologue reasoning is useful or not’. https://www.oneusefulthing.org/p/something-new-on-openais-strawberry
-
Drew Breunig (GeoSpatial and Data Guy): “It’s more expensive, can handle edge case (albeit embarassing) questions, but still makes errors. Where would you use this in production that you wouldn’t use 4o, vanilla or fine-tuned? For who and what is this for?” https://news.ycombinator.com/item?id=41532790
-
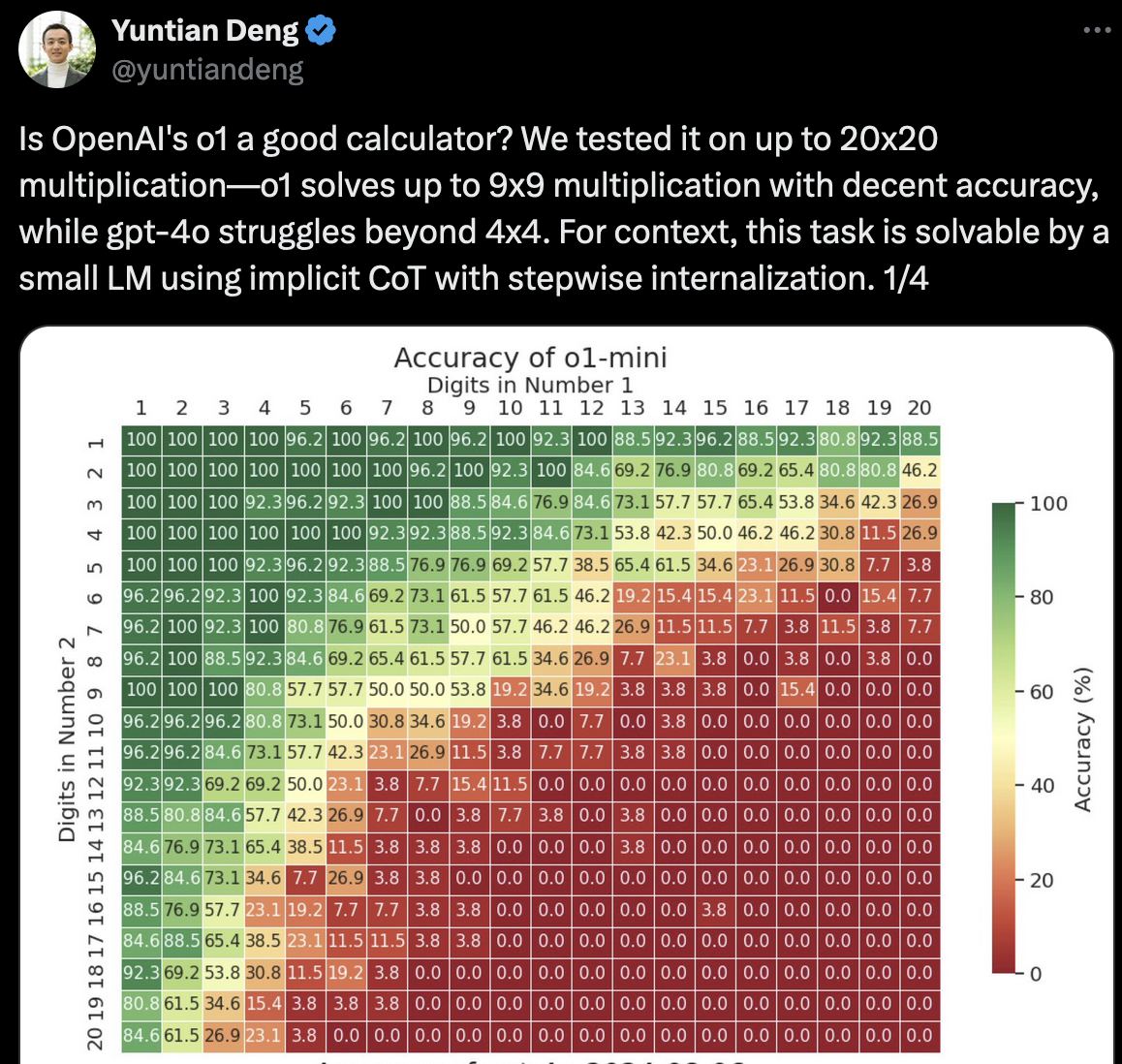
Via Yuntian Deng from UWaterloo, o1 is incrementally, a better ‘calculator’ than 4o, but, as the commentariat noted; “I did not sit through years and years of smug systems devs bemoaning that modern software is too bloated and complex and layered to watch people deploy entire data centres to perform something you can do with a single x86 instruction” - https://x.com/mountain_ghosts/status/1836398403351130166
Incidentally, any parents of young children or people who know developmental psychology able to point me at a similar ‘chart’ for accuracy of times-tables in kids?
Anyway, while I was writing this; Google alerts went off; so it seems The S*n picked up on some of my comments around AI; The bad grammar isn’t mine, and apologies to my scouse bretheren for being featured in that paper (at least it’s the Ireland one…)